
AI Brand Sentiment Analysis
Measure how AI engines describe your brand
AI search visibility tells you whether you appear. Sentiment analysis tells you how AI engines talk about you, criterion by criterion, vs every competitor in your category. Surface bias, misinformation, and hallucinations the moment they emerge.
 ChatGPT
ChatGPT Claude
Claude Gemini
Gemini Perplexity
Perplexity DeepSeek
DeepSeek Grok
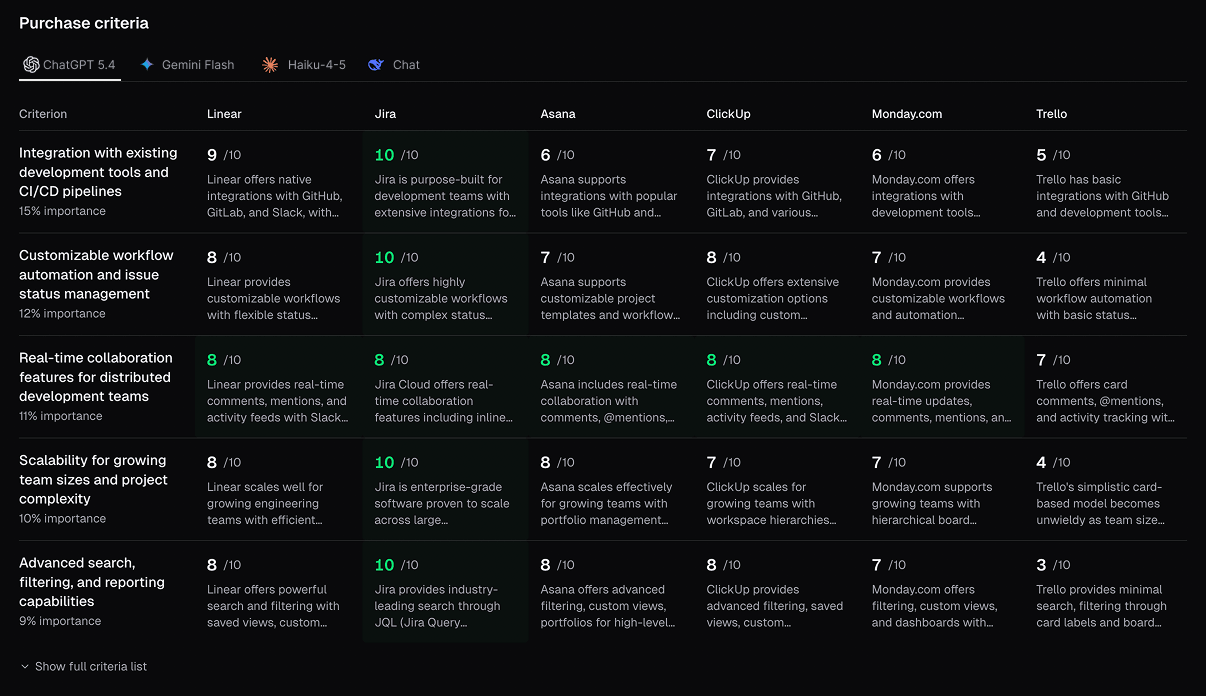
GrokPurchase criteria grid: you vs the market, in one view
The flagship view. Rows are the purchase criteria buyers in your category care about. Columns are you and every tracked competitor. Each cell shows the sentiment score and a one-line summary of what AI says about you on that dimension. Switch the active model in the tab strip to see how each engine differs.
The problem
Visibility is not the same as a positive answer.
Your brand can be cited in every AI response and still lose deals because the model frames you as expensive, hard to integrate, or weak on support. Worse, generative engines hallucinate features, invent pricing, and recycle outdated reviews as if they were current. Without per-criterion sentiment tracking, every prospect conversation that starts with an AI search is a black box.
How it works
From sign-up to signal in minutes.
Configure the purchase criteria that matter in your category
Whaily proposes the criteria buyers in your industry actually use, drawn from the AI responses themselves: pricing, integrations, support quality, security posture, performance, onboarding, vertical fit, and so on. Edit the list, add your own, and the rest happens automatically.
We score sentiment per criterion across every model and competitor
On every prompt run, Whaily extracts the claims each AI model makes about you and each tracked competitor for each criterion. Claims become structured scores (0 to 10), aggregated across runs, and visualised as a side-by-side grid so the deltas are obvious.
Drill into bias, misinformation, and hallucinations
Click any cell to see the source quotes, the responses they came from, and the models that produced them. Flag claims that are factually wrong, contradicted by your own documentation, or invented entirely. The audit trail is your evidence when you escalate to a model provider or update your category content.
What you get
Everything you need, in one place.
Per-criterion scoring
Every purchase criterion gets a 0-10 sentiment score per brand per model. Compare on price, integrations, support, security, and the dimensions specific to your category.
Side-by-side competitor comparison
See your scores next to every tracked competitor in the same view. The cells where they outscore you are the cells where you are losing the AI-mediated buyer.
Bias detection
Spot when a model is consistently negative on you and consistently positive on a competitor for the same criterion. That is bias, not noise, and it is correctable with the right content.
Hallucination flagging
Mark factually wrong claims (made-up features, invented pricing, contradicted facts) so you can track misinformation per model over time and escalate when it matters.
Sentiment trend over time
Watch each criterion score shift week over week. A content push, a launch, or a press cycle either moves the needle or it does not, and now you can see which.
Source drill-down
Every cell is a click into the exact response excerpts that produced the score. Pin the worst quotes, share them with the team, and turn them into the next content brief.
Why it matters
The G2 criterion AI buyers now expect.
AI brand sentiment analysis is the discipline of evaluating how AI platforms interpret and present brand-related information, detecting biases, misinformation, and hallucinations. It is now a buyer-side requirement, not a nice-to-have. When prospects compare vendors through ChatGPT, Gemini, or Perplexity, the sentiment of the answer shapes the shortlist before a salesperson sees a lead.
Whaily was built around this measurement. Every AI response we capture for your tracked prompts is decomposed into per-criterion claims. A sentence like "Vendor A has solid integrations but pricing is opaque" yields one positive score on integrations and one negative score on pricing, with the source quote attached. The aggregation runs across every model you track, every prompt you care about, and every competitor in your category, so you see the full picture, not a single anecdote.
The same pipeline surfaces hallucinations and misinformation as a side effect. When a model invents a feature you do not ship or quotes a price you have never charged, that is a flagged claim in the audit log. You decide whether to correct your own content, update third-party listings, or escalate to the model provider. Either way, you have the evidence and the timeline.
Questions
The short answers.
What is AI brand sentiment analysis?+
How is this different from generic sentiment analysis on social media?+
How do you detect AI hallucinations about my brand?+
What are purchase criteria and where do they come from?+
Can I see sentiment per AI model?+
How quickly does sentiment analysis update?+
Ready to be recommended by AI?
Start free. See your first insights in minutes.